前言
NVDLA的软件栈主要分为两个部分:Compiler与Runtime,由于Compiler与硬件无关,所以可以在我们自己的开发机器上编译运行调试,理解起来也较为方便;而Runtime与硬件有关,调试非常困难,官方提供的预构建的文件又都是针对64位ARM/RISC的操作系统,这对没有合适的板卡,即仅搭载了32位处理器的ZYNQ 7000系列的开发板上编译Runtime带来了很多难以解决的问题。
Loadable文件是两者之间通信的媒介,本文记述一下Loadable文件的组织结构和解析方法,既然不能吃官方给的饭,那么可以试一试自己在SOC上做一份调度的算法,解读Loadable文件就是第一步。
Github Repo:https://github.com/LeiWang1999/nvdla-parser
首先,我们使用nvdla_compiler编译生成一个loadable文件,你可以在这个连接下载到预先编译好的文件,里面已经包含了生成的fast-math.loadable:
1 | |
简单介绍使用到的参数:
fast-math是什么?
在编译期间可以做一些硬件无关的优化,例如算子融合、内存重用,这些设置可以在Profile.cpp里找到。
1 | |
最常使用的,也是官方给的默认参数-fast-math指令编译的配置如下:
1 | |
在aarch64的模拟器里运行runtime、fast-math和default的速度差异是非常明显的,
为什么要指定int8模式?
因为nvsmall的配置是不支持16位运算的,此外,有关NVDLA的INT8量化,可以看这篇post。
关于Compiler还做了哪些事情,我们在以后的文章里讨论,这里我们只需要关心的是Compiler最后生成的目标文件,即Loadable。
在sw的仓库里,我们可以找到loadable.fbs文件,说明loadable是使用FlatBuffers做位压缩手段,这将是这篇博客的开始。
1. FlatBuffers 简介
FlatBuffers是一个开源的、跨平台的、高效的、提供了C++/Java接口的序列化工具库。它是Google专门为游戏开发或其他性能敏感的应用程序需求而创建。尤其更适用于移动平台,这些平台上内存大小及带宽相比桌面系统都是受限的,而应用程序比如游戏又有更高的性能要求。它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而不需要任何解析开销。
简单来讲,我们需要在流中传输一个对象,比如网络流。一般我们需要把这个对象序列化之后才能在流中传输(例如,可以把对象直接转化为字符串),然后在接收端进行反序列化(例如把字符串解析成对象)。但是显然把对象转成字符串传输的方法效率十分低下,于是有了各种流的转换协议,FlatBuffers也是其中一种。
本文不具体讨论其是如何压缩对象,具体可以参照官方的文档。这里借用简书中的一个例子:
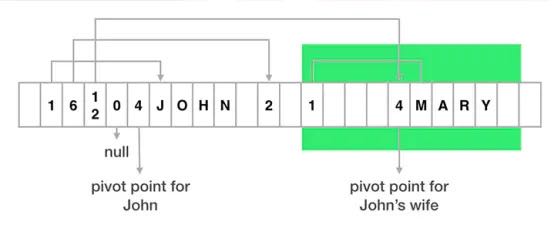
- 每一个存储在FlatBuffer中的对象,被分割成2部分:中心点(Pivot Point)左边的元数据(vtable)和中心点右边的真实数据。
- 每个字段都对应vtable中的一个槽(slot),它存储了那个字段的真实数据的偏移量。例如,John的vtable的第一个槽的值是1,表明John的名字被存储在John的中心点右边的一个字节的位置上。
- 如果一个字段是一个对象,那么它在vtable中的偏移量会指向子对象的中心点。比如,John的vtable中第三个槽指向Mary的中心点。
- 要表明某个字段现在没有数据,可以在vtable对应的槽中使用偏移量0来标注。
loadable.fbs由Schema语言组织,我们不需要添加定义,只需要考虑理解和读取。
1.1x 安装FlatBuffers
1 | |
确认是否安装成功:
1 | |
在笔者写这篇博客的时候,flatc的版本已经是v1.12.0了,在官方仓库里的flatbuffers.h文件里可以发现,其使用的flatbuffers的版本是1.6.0:
1 | |
虽然flatterbuffers声称其有非常好的前后兼容性,但是v1.12.0的程式与官方的代码有些对不上号,为了方便起见,这里在安装的时候把版本回退到v1.6.0.
生成loadable_generated.h,在我们的项目里引入这个头文件就可以读取loadable了。
1 | |
FlatBuffers是轻依赖的,生成的头文件也只需要依赖flatbuffers.h,在我的项目目录下,这样组织文件,flatbuffers文件夹直接拷贝flatbuffers/include目录下的flatbuffers文件夹,但其实只需要拷贝flatbuffers.h就可以:
1 | |
2. 解析loadble
看examples/0.loadable.read.cpp文件,读取了loadable文件的root_type,然后打印出其各个成员的size,测试我们是否是真的读取了loadable。
本章节的2.1-2.19分别对应examples文件夹下的9个文件的输出,即loadable.fbs里定义的root的组织结构的具体内容:
1 | |
version不明白是用来做什么的,这里代表的不是使用的flatbuffers的版本,估计是compiler开发的版本?。
task_list是任务列表,就两个任务,第一个是DLA、第二个是EMU,应该分别代表硬件加速核和仿真器,tasklisk的address_list代表了每个task访问地址的列表。
memory_list是内存列表,我们可以通过task_list->address_list拿到addres_list的index,然后通过address_list->memory_id找到读取哪一块内存。
address_list是地址列表
event_list在runtime里似乎没有用到
blobs是存储数据的地方,分析blob的每个字段都有name,对应了memory里的name。
tensor_desc_list定义了输入层和输出层的tensor描述。
reloc_list\submit_list也不知道干嘛的
2.1x version
1 | |
2.2x task_list
1 | |
2.3x memory_list
1 | |
2.4x address_list
1 | |
2.5x event_list
1 | |
2.6x blobs
1 | |
2.7x tensor_desc_list
1 | |
2.8x reloc_list
1 | |
2.9x submit_list
1 | |
3 读取blobs里的数据
3.1x 读取网络描述信息
演示一下如何读取网络的定义,首先拿到task访问的第一个地址,再根据这个地址拿到name。
1 | |
通过比对name,得到blob_index,拿到对应的blob数据。
1 | |
接着,我从kmd的仓库里把dla_interface.h文件拷贝了过来,之前不懂为什么nvdla在定义这些结构体的时候它都要对齐,想来都是为这个准备的。
1 | |
然后直接把blob的指针强制转化:
1 | |
读取出来数据,经过验证数据都是正确的。

* desc_index代表的数据是task访问内存的下标,我们可以根据这些数据一次访问到其他所有的结构体。
3.2x 封装Parser
最后,封装了一个Parser对象,直接给loadable对象即可把几个关键的结构体都读取出来:
1 | |
Debug信息:
1 | |
Comments